Why AI initiatives fail


Six months ago, the budget was approved. The vendor was selected. The roadmap was drawn. The proof of concept ran clean in a sandbox, and the executive summary called it transformational.
Then, quietly, the initiative slid past its production date. The slides stopped getting updated. The CFO asked a question nobody had a good answer to. Somewhere between the demo and the deployment, the project lost its way.
This pattern repeats across European boardrooms every quarter. AI initiatives failing is no longer a fringe story, it is the dominant outcome of enterprise AI investment. MIT, Gartner, RAND, BCG and S&P Global have all converged on the same diagnosis, just with different numbers attached.
This article unpacks why AI initiatives fail, what the verifiable research says about the failure rate, the seven recurring patterns we see inside European mid-market and large enterprises, the real cost of getting it wrong, and the early warning signs that show up well before a project officially stalls.
Key takeaways
- Roughly 95% of enterprise generative AI pilots produce no measurable P&L impact, according to MIT NANDA's 2025 State of AI in Business report.
- The failure pattern is rarely technical. It is operational: weak success criteria, fragile data foundations, missing MLOps, and no feedback loop after launch.
- European SMEs face a sharper version of the problem. 99.8% of EU enterprises are SMEs (Eurostat), only 17% of small EU firms had adopted AI by 2025, and 70.9% of non-adopters cite lack of expertise as the reason.
- The cost of failure now includes regulation. Under the EU AI Act, fines can reach up to €35 million or 7% of global turnover for prohibited-practice violations.
- Production maturity, not model novelty, is what separates the 5% from the 95%.
What the data says about AI initiatives failing
The most-cited 2025 study is the MIT Project NANDA report, The GenAI Divide: State of AI in Business 2025. Based on 52 executive interviews, 153 senior-leader surveys and analysis of 300+ public AI initiatives, the study found that only 5% of integrated AI pilots extract meaningful value, while the rest remain stuck without measurable P&L impact. Enterprise generative AI spend in scope reached $30 to 40 billion.
Gartner's predictions for 2025 and 2026 reinforce the same direction. By the end of 2025, Gartner expects 30% of generative AI projects to be abandoned after proof of concept. Through 2026, the firm estimates 60% of AI projects will be abandoned due to inadequate AI-ready data, while more than 40% of agentic AI projects are forecast to be cancelled by the end of 2027.
The RAND Corporation puts the historical AI project failure rate at over 80%, twice the rate of comparable non-AI IT projects. S&P Global Market Intelligence reports that the share of companies abandoning most AI initiatives jumped from 17% in 2024 to 42% in 2025, with the average company scrapping 46% of proofs of concept before production. Stanford HAI's AI Index 2025 shows AI use by organisations reached 78%, but adoption and value remain very different conversations.
The European picture is sharper. Eurostat's December 2025 release shows 20.0% of EU enterprises with 10 or more employees used AI in 2025, up from 13.5% in 2024. Adoption ranges from 55.0% among large enterprises to 17.0% among small firms.
The most-cited barrier among non-adopters of AI are:
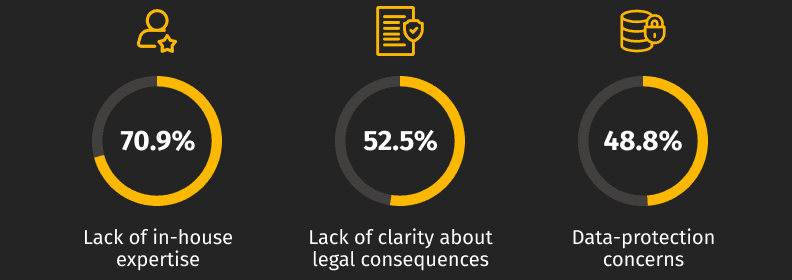
The seven core reasons AI initiatives fail
Across European mid-market and large enterprise engagements, seven recurring failure modes account for the overwhelming majority of stalled or abandoned AI initiatives. They rarely show up alone. The presence of two or three is a reliable predictor that the initiative will not reach production at scale.
Reason 1. Chasing unicorns
The initiative starts with a glamorous use case: predict customer churn before the customer thinks about leaving, or generate fully personalised marketing copy for every segment in real time. The success criteria are framed in adjectives, not numbers. The business outcome that the AI is supposed to move is never specified. The KPI is, in effect, deploy AI.
RAND's 2024 root-cause study found that the single most common cause of AI project failure is misunderstanding and miscommunication about the intent and purpose of the project. Deloitte's Q4 2024 State of Generative AI in the Enterprise report shows 26% of leaders rank difficulty identifying use cases as a top-three barrier.
The fix is unglamorous: a quantified business hypothesis with target metric, baseline, expected delta and decision threshold, signed off by an accountable business owner before a single notebook is opened.
Reason 2. Mismanaging the change
The pilot was scoped for one workflow. By month four, it covers three workflows, two business units, and a new compliance requirement nobody anticipated. The data engineers are blocked on a CRM migration that was supposed to finish last quarter. The original sponsor moved roles. The new sponsor wants a demo before committing the budget.
This is classic transformation-program failure dressed up in AI clothing. Gartner's April 2026 research on AI projects in infrastructure and operations found that 57% of leaders who reported failures said the cause was expecting too much, too fast. Scope creep, dependency drift and unstable sponsorship hollow out the operating model the AI depends on.
Fixed scope, fixed cadence and explicit dependency tracking are not optional — they are the operating system.
Reason 3. Chaos engineering
The team is six months in. Jupyter notebooks proliferate. There are now four candidate models, two evaluation frameworks, three vector databases, and a shared spreadsheet tracking which experiment is the real one. Every meeting introduces a new metric. Nothing ships.
MIT NANDA's research documents this as the structural divide between mid-market firms, which move from pilot to implementation in roughly 90 days, and large enterprises, which take nine months or longer. Gartner reports an eight-month average prototype-to-production cycle. The discipline that breaks the cycle is not more talent — it is operating constraints: a fixed evaluation harness, a documented model-selection criterion, time-boxed experiment cycles, and a written definition of done the team can hold itself to.
Reason 4. Garbage in, garbage out
The data is everywhere and nowhere. Customer records live in three systems with three different IDs. Product catalogues drift across regions. Half the relevant signal sits in PDFs in a SharePoint folder nobody owns. The model trained on the cleaned 5% slice performs well in the notebook and falls apart on the other 95%.
Gartner predicts that through 2026, 60% of AI projects will be abandoned due to a lack of AI-ready data, with 63% of organisations lacking or unsure of the right data-management practices for AI. Informatica's CDO Insights 2025 ranks data quality and readiness as the top obstacle to AI success at 43%.
AI-ready data is a stricter standard than analytics-ready data: it requires continuous quality, active metadata, lineage and governance applied at the cadence the model consumes data, not the cadence the BI team reports.
Reason 5. Sticks and stones
The data platform was built for monthly reporting. The AI platform is three notebooks, two GPU instances, and a Slack channel called #ml-experiments. There is no feature store, no model registry, no shared evaluation framework, no deployment pipeline. Each new model is built from scratch by whoever is on the team that quarter.
McKinsey's 2025 State of AI survey found that organisations reporting significant returns from AI are markedly more likely to have redesigned end-to-end data workflows before scaling. BCG's Where's the Value in AI? (October 2024) found that only 4% of companies have cutting-edge AI capabilities consistently across functions, while 74% have yet to show tangible value. A shaky foundation is not a problem you can solve with a bigger model, it is a problem you solve by treating data and AI infrastructure as the product.
Reason 6. To infinity and beyond
The model works in the notebook. Production is a different story. The CI/CD pipeline does not know how to package a Python environment with three GPU dependencies. The drift monitor was a slide in a deck. The fallback when the model is wrong is to log it and review later. Six weeks after launch, the model is silently degrading and nobody is paged.
Industry research and primary surveys converge on the same conclusion. Roughly 80% of ML models never reach meaningful production (RAND, 2024), and Gartner reports only 48% of AI projects move from prototype to production, with an average cycle of eight months. Of the models that do ship, many degrade silently because monitoring, retraining and rollback are not built in. The fix is MLOps maturity treated as a priority-zero capability: deployment pipelines, evaluation in production, drift detection, observability, on-call ownership, and a defined retraining cadence. Without those, going live is just the moment the technical debt starts compounding.
Reason 7. The human with AI
The model shipped. The dashboard went live. Adoption flatlined. The sales team kept using their spreadsheet. The support team turned the AI suggestions off in their first week. The product manager who owned the initiative is now on a different team. No structured feedback loop was ever built. The model has not been retrained since launch.
MIT NANDA frames this as the learning gap: tools that do not retain feedback, adapt to context, or improve over time. 90% of workers use personal AI tools daily, while only 40% of organisations have official LLM subscriptions, creating a shadow AI economy that the official programme is competing against rather than absorbing. McKinsey's research is unambiguous: workflow redesign has the single largest effect on EBIT impact from generative AI of the 25 attributes tested. AI value is unlocked by product management, not just by engineering.
Summary: the seven failure modes and how to overcome them
Each of the seven failure modes is recoverable but only if it is caught early enough to act on. The table below maps each pattern to its root cause and the intervention that breaks it.
| Reason | Description | How to overcome |
|---|---|---|
| Chasing unicorns | Glamorous use case with no quantified business hypothesis or accountable owner. | Signed-off target metric, baseline, expected delta and decision threshold before any build. |
| Mismanaging the change | Scope, schedule and dependencies drift; sponsorship changes mid-flight. | Fixed scope, fixed cadence, explicit dependency tracking, named executive sponsor. |
| Chaos engineering | Endless experimentation; competing models, frameworks and metrics; nothing ships. | Time-boxed experiments, fixed evaluation harness, written definition of done. |
| Garbage in, garbage out | Fragmented, low-quality, ungoverned data that breaks outside the pilot slice. | Treat data as a product: continuous quality, active metadata, lineage, governance at model cadence. |
| Sticks and stones | Reporting-grade data platform and improvised AI platform; no shared foundations. | Engineer the foundation first: feature store, model registry, evaluation framework, deployment pipeline. |
| To infinity and beyond | Model works in the notebook but fails at production: no MLOps, no monitoring, silent drift. | MLOps maturity as a P0: pipelines, observability, drift detection, on-call ownership, retraining cadence. |
| The human with AI | Low adoption, no feedback loop, no product owner, model never improves after launch. | Product management discipline: workflow redesign, structured feedback capture, retraining triggered by use. |
The real cost of failed AI initiatives
The cost of AI initiatives failing extends far beyond sunk technology spend. The most visible line item is wasted budget. MIT NANDA estimates $30 to 40 billion of enterprise generative AI investment is currently producing no measurable P&L impact. Stanford HAI puts global corporate AI investment at $252.3 billion in 2024, and IDC projects worldwide AI spending of $307 billion in 2025 rising to $632 billion by 2028. Even a 30% abandonment rate puts hundreds of billions of dollars of investment at risk.
Time-to-market is the second cost. Gartner reports an average eight-month prototype-to-production cycle, and MIT NANDA shows that large enterprises take nine months or longer to move from pilot to implementation. Every month a competitor reaches production first is a month of compounding customer learning.
Trust erosion follows. S&P Global's 2025 research found that companies with above-average AI failure rates are 77% more likely to report reputational damage, 41% more likely to face customer resistance, and 36% more likely to face internal staff resistance. In the EU, regulatory costs amplify all of the above. The EU AI Act, in force since August 2024, carries fines of up to €35 million or 7% of global annual turnover for prohibited-practice violations, with the bulk of high-risk obligations applying from August 2026.
The Dutch childcare benefits scandal (Toeslagenaffaire) is a case study every European board should know. The Dutch Tax Administration used a self-learning risk-scoring algorithm that wrongly accused approximately 35,000 families of childcare-benefit fraud, resulting in over 2,000 children being removed from their families. The third Rutte cabinet resigned in January 2021 over the affair. The technology debt became a political and human crisis.
The cost of AI initiatives failing goes far beyond technology spend

Early warning signs that an AI initiative will fail
These signals show up well before the project officially stalls. Two or more is a clear trigger to intervene.
- The pilot has been in production-readiness review for more than six months with no firm go-live date.
- No business sponsor at executive level owns the initiative's P&L outcome.
- Success criteria are described in capabilities (the model can predict X) rather than business deltas (reduce returns by N percentage points within Q3).
- The data pipeline feeding the model is a manual extract on a recurring cadence rather than a governed, monitored, continuous flow.
- There is no shared evaluation framework that the team agrees represents good enough to ship.
- The deployment plan does not specify on-call ownership, drift monitoring or a retraining trigger.
- Adoption by the end users it is supposed to serve is not being measured, or is being measured and declining.
Two or more signals firing? It's time to act.
Talk to our AI engineerHow AI Engineering by Grid Dynamics helps
The patterns above are not unique. They are predictable, diagnosable and fixable, provided the operating model around the AI is treated with the same rigour as the model itself.
AI Engineering by Grid Dynamics is the European unit of Grid Dynamics, built specifically for mid-market customers across Retail, FinTech, Manufacturing, Energy and Technology verticals. Our forward-deployed engineers embed inside your team in three to four weeks, working in your sprints, your codebase and your governance model, with delivery centres across European time zones.
The services map directly to the seven failure modes. Technology consulting and AI strategy address the unicorns and change-management problems. AI engineering and data platform implementation tackle garbage in, garbage out and the shaky foundation. MLOps, AIOps and our Temporal-based agentic platform launched in September 2025 solve the production and orchestration problems. Engineering talent services close the product-management and adoption gap.
The aim is not to leave you dependent on us. Knowledge transfer is designed in from day one, and most engagements have a defined exit so the capability stays with your team. Most of our European clients are able to move a stalled AI initiative to production in eight to twelve weeks once the operating model is in place.
Final thoughts
The 95% figure is not a verdict on AI. It is a verdict on how enterprises run AI programmes. The 5% that succeed are not winning because their models are better. They are winning because their success criteria are sharper, their data foundations are stronger, their MLOps are real, and their product feedback loops actually loop.
European companies have a narrower path to value than their US peers: smaller AI budgets, a denser SME economy, a tighter regulatory frame and a shallower domestic AI talent pool. The compensating advantage is execution discipline. The companies that close the GenAI divide first in Europe will be the ones that treat AI as an operational capability, not a science experiment.
FAQ
What is the biggest challenge in implementing AI?
The biggest single challenge is the absence of AI-ready data. Gartner predicts that 60% of AI projects will be abandoned through 2026 due to inadequate data foundations, and 63% of organisations either lack or are unsure of the right data-management practices for AI. Talent shortages, weak success criteria and missing MLOps are close behind, but data is the recurring root cause across primary research.
How many AI projects actually reach production?
The most-cited figures put the production rate between 5% and 48%. MIT Project NANDA's 2025 study found that only 5% of integrated enterprise generative AI pilots produce measurable value. Gartner's May 2024 survey reported that 48% of AI projects move from prototype to production, with an average cycle time of eight months. RAND estimates that historically over 80% of AI projects have failed to reach meaningful production.
What causes AI pilot projects to fail at scale?
Scaling failure is concentrated in three areas: data foundations that work for a controlled pilot but break under production volume and variety, MLOps maturity that is missing or improvised, and the absence of a real product feedback loop that adapts the model to actual user behaviour. McKinsey's 2025 State of AI survey shows that workflow redesign has the single largest impact on generative AI's EBIT contribution.
How can companies improve AI implementation success rates?
The pattern shared by high performers is consistent: a quantified business hypothesis signed off by an accountable executive sponsor, AI-ready data treated as a product rather than a project, an MLOps and evaluation harness built before the first model goes live, and a workflow redesign that puts the AI inside the operating process rather than next to it. MIT NANDA's research adds one further point: tools built by external partners succeed roughly twice as often as those built entirely in-house.



