The 90-Day Ramp Problem: Why Most Staff Augmentation Engagements Fail to Deliver in Q1

Let's start with the part nobody wants to say out loud
Staff augmentation has a ramp problem and honestly it's not a new one. The people who feel it most aren't the vendors — it's the Engineering Directors who signed off on the engagement, took the business case upstairs, and then spent a quarter watching the numbers go nowhere.
The story tends to follow the same arc. Engagement kicks off, engineers seem solid, and over the first couple of weeks everyone's finding their feet. By Week 4 something is moving but not at the pace anyone expected. Week 6 you're doing arithmetic you don't want to be doing including how much actually shipped, how many hours your internal team spent fielding questions from people brought in to add capacity, not consume it. By the close of Q1 there are three months of invoices and maybe four or five weeks of output you'd genuinely call meaningful.
Then comes the part where you need to explain it to someone above you.
We've been in enough of those conversations, on both sides of the table, to have a clear picture of what's going on. It's not a vendor quality problem. It's not a talent problem either, though that's usually where the blame ends up. The problem is structural and it starts earlier than most people think.
Structured onboarding improves productivity by over 60% and cuts time-to-contribution by around 40% and those figures apply to permanent hires with job security and a genuine reason to push through the friction of early weeks. Augmented engineers are working from a different starting position. They show up without organizational history, often don't know a single person on the team, and there's a quiet expectation of usefulness that kicks in almost immediately. A permanent hire taking three months to find their footing is frustrating. An augmented engineer taking three months probably costs you the quarter.
It’s not the engineers, it’s the setup
When a ramp goes badly the post-mortem almost always circles back to the engineers. Were they senior enough, did they have the stack experience their CV suggested, should vetting have flagged something. It's not an unreasonable place to look but it’s usually the wrong one.
By the time an augmented engineer opens their first ticket, the shape of the engagement is already largely determined, and skill level has very little to do with it.
What mattered was the two weeks before they arrived. Whether anyone actually owns the integration. Whether the team has ever worked out what "productive in 30 days" means. When that structure isn't there, it doesn't really matter what the engineer is capable of.
The 8 reasons it keeps happening
Across more than fifty engagements the pattern is frustratingly similar. It's never one critical failure — it's eight smaller ones, none of them fatal on their own, but together capable of consuming an entire quarter before anyone's worked out what went wrong. None of them are mysterious, and none require significant investment to fix. They just require someone to actually own fixing them, which is itself one of the problems.
| Reason | Problem | Fix |
|---|---|---|
| Toolchain access delay | GitHub, Jira, VPN, cloud environments — each owned by a different team, each a separate request, none treated as urgent. The engagement starts on paper Day 1. In practice, it starts around Day 8 to 12. Two sprints gone before meaningful code gets written. | Treat access as a pre-start deliverable. Provision and verify everything 5 business days before the engineer arrives. One person owns a checklist, confirms it works end to end. Thirty minutes of effort — still the most reliably skipped step. |
| No named onboarding owner | Ask who's accountable if the ramp goes badly and you'll get a pause, then something noncommittal. Blockers don't get flagged and something a ten-minute conversation could fix in Week 1 is still there in Week 4, slightly bigger | Name one person who is explicitly accountable. Not involved, not supportive — accountable. Blockers get flagged, small problems get caught early, and things a ten-minute conversation could fix don't compound into Week 4 problems. |
| Vague first-30-days scope | "Get familiar with the codebase" isn't a plan. Without a defined outcome, engineers default to passive mode — reading docs, attending meetings, exploring the repo. Knowledge increases, nothing ships, and there's no signal about whether integration is on track | Define the first 30 days as an outcome. A scoped, low-stakes deliverable forces the engineer through the full delivery loop and surface gaps while they're still cheap to fix. |
| Knowledge transfer left to chance | Documentation covers the what, not the why. Every team has a senior engineer who holds the real knowledge. When transfer depends on that person having time, it happens when it happens, if at all. | Build knowledge transfer from Week 6, not Week 12. Three layers work: documentation access, live shadowing and pairing, and a hands-on task that builds understanding through doing rather than reading. |
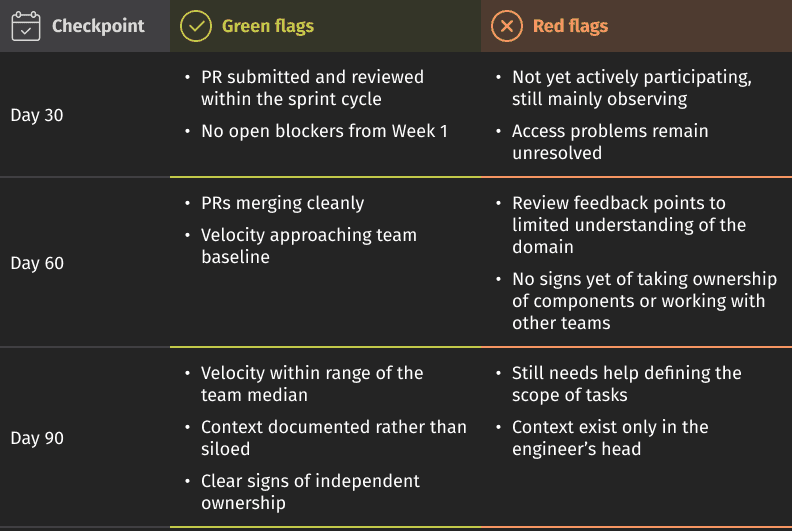
| No milestone checkpoints | A Day 90 review doesn't help you manage a ramp by then you're doing a post-mortem on a quarter that's already gone. Issues that surfaced in Week 3 have been compounding quietly for two months before anyone sees them. | Structured checkpoints at Day 30, 60, and 90 — alignment conversations, not report cards. Day 30 in particular surfaces blockers while changes are still cheap. An hour of honest conversation there regularly saves weeks |
| Autonomy mismatch | The client brought in a senior engineer and expected independent ownership. The engineer walked into an unfamiliar system and was waiting for enough context before acting. Nobody addresses the gap, and the working relationship quietly breaks. | Stage autonomy deliberately rather than assume it. One named technical person tracks progression from guided work through to independent ownership — without that, the transition happens at nobody's pace |
| Team culture opacity | Every team runs on informal conventions nobody documented — what a thorough PR really looks like, what "done" actually means, when to escalate, how on-call works versus how the runbook describes it. Permanent hires absorb this over months. Augmented engineers only have weeks, so they guess and guessing slows delivery. | One focused conversation early on, covering how decisions get made and how work actually flows. It takes about an hour and prevents months of small misunderstandings compounding into slower delivery. |
| No exit documentation protocol | Augmented engineers accumulate context that exists nowhere in writing — architectural reasoning, legacy workarounds, why the obvious solution doesn't work here. When the engagement ends, that context walks out with them | Treat knowledge capture as ongoing, not a wrap-up task. Engineers document and share what they're learning while the context is fresh and |
None of these are individually catastrophic, we’re talking about a few days of access delay, an expectation not spelled out, a feedback loop running slightly behind. Any single issue is manageable on its own. The problem is that they rarely show up on their own and by the time the pattern becomes visible the quarter is mostly gone. Month one goes to orientation. Month two is a partial contribution while still piecing things together. Month three is when output starts to look like what was promised. Three months of spend, one month of delivery. That's not a talent problem. It's what happens when nobody treats integration as something that needs to be designed.
Looking for a proven staff augmentation partner?
Talk to usThe data says the same thing
Deloitte's research finds that workers who experience highly effective onboarding are 18 times more likely to feel strongly committed to their organization and that one in three new hires leaves within the first six months.
At the same time, McKinsey mentions that successful companies introduce structured onboarding with clear 30, 60, and 90-day expectations while noting how this approach allowed one company to lift the share of new employees meeting their first performance goals from 15% to 75%.
None of this is specific to staff augmentation, which actually makes the situation more concerning. The numbers refer to permanent employees who have job security, support from the organization, and every reason to push through the challenges of their first weeks. In contrast, augmented engineers often lack these advantages. They usually have no background in the system, no established relationships, no long-term investment in the outcome, and are expected to start contributing almost right away. There is little room for mistakes, and the consequences of errors are higher than most expect.
What a structured ramp actually looks like
The methodology that consistently works runs across a set of sequential phases and the sequencing matters more than most teams expect. Skipping ahead or treating the phases as loose guidelines is one of the more reliable ways to burn the first quarter..
Documentation has to be validated before the engagement starts, architecture references, coding standards, the context a new engineer actually needs, not assembled on the fly after Day 1. A named buddy is assigned and briefed before the engineer arrives, handling daily check-ins, live shadowing, and cultural integration through the early weeks. Communication runs on a defined cadence — daily standups, regular 1:1s, and monthly reviews, each with a clear purpose and the right people in the room. Accountability is assigned explicitly before anyone writes a line of code, with one named person owning ramp success end to end.
Pre-onboarding runs from Day 14 through Day 1 — access provisioned, documentation ready, a buddy assigned, and the Day 1 agenda is already in everyone’s calendar. Nothing to sort out on arrival. Over the first two weeks, the focus is on orientation, completing a guided task, and having an early checkpoint to address any issues. By Week 6, the engineer should be working independently and reach the first alignment checkpoint at Day 30. From Weeks 7 to 10, the engineer should take ownership of a component, collaborate with other teams, lead a knowledge-sharing session, and complete a Day 60 review. In the final phase, the engineer should reach full sprint velocity, and the Day 90 assessment will confirm the transition to regular work.
The three review checkpoints at Day 30, 60, and 90 are alignment conversations, not report cards and each has clear signals worth watching for.
A full 90-day integration playbook, with week-by-week milestones, checkpoint forms, a pre-start checklist, and accountability structure, is what turns this from a framework into something you can actually implement.
How to tell if there's a system behind their pitch
Talent matters. Rate matters. Speed of placement matters. But none of that tells you whether the first 90 days will work. For that you need to understand how the engagement is structured and a lot of vendors, if you push them on specifics, won’t have a clear answer.
Four questions worth asking before anything gets signed:
- Who owns ramp success, by name? Not "the team supports onboarding." A name, a role, explicit accountability. If the answer wanders, accountability doesn't exist.
- What does the engineer deliver in the first 30 days? If the answer is "get familiar with the codebase," Month 1 is already lost. Look for a concrete, outcome-focused answer that includes what gets built and what on-track looks like by the end of Week 2.
- Where are the early checkpoints? Ask specifically about Day 30. What you want is for Day 30 to be a conversation that adjusts scope and surfaces blockers while changes are still cheap, not a formal performance review. A vendor without that built in is essentially planning to find out what went wrong at the end of the quarter.
- How does knowledge get retained when the engagement ends? "We'll document at the end" means it leaves with the engineer. Ask for the specific mechanism regarding how context gets captured during the engagement, not after.
It’s also a good idea to ask how engineers are matched to the technical domain before the engagement starts. Stack fit cuts the orientation burden significantly and is one of the more reliable ways to get early contribution without a long shadowing period.
These questions aren't a trap. They're a way of finding out whether there's a system behind the engagement. The difference between a slow ramp and a productive first quarter almost always comes down to that.
What sets us apart
A 90-day playbook only works if the right people are putting it into action. Many vendors miss this, but it’s what makes AI Engineering different.
We only place engineers from the top 10% of candidates. Our process includes three to four interview rounds that look at technical skills, fit with your tech stack, and how well someone will work with your team. We set a high standard on purpose, because a slow start isn’t just about delivery, it can affect trust with everyone involved.
After an engineer joins the team, a dedicated Delivery Manager stays involved the whole time. They don’t just check in every few months, they track performance, collect feedback from both sides, and spot issues early so they don’t grow. This hands-on approach is what makes our playbook work in real-world situations.
But our support doesn't stop there. At Grid University, our engineers keep learning, staying up to date with new technologies, building expertise in specific fields, and sharpening the skills that matter most for your environment. We also monitor performance and feedback, so development is always practical and directly connected to how each engineer is doing in real situations.
Our engineers are backed by the entire Grid Dynamics community. They have access to our broad engineering network, the CTO office, regular events, shared tools and accelerators, and a culture of sharing experience across regions and industries. When challenges come up, they always have support.
Tired of the 90-day ramp problem? Hire engineers who come with a plan
Talk to us


